
✔ MoBA: Mixture of Block Attention for Long-Context LLMs представляет собой революционное решение для обработки длинных контекстов в языковых моделях. Вот что в нём интересно:
• Инновационная архитектура:
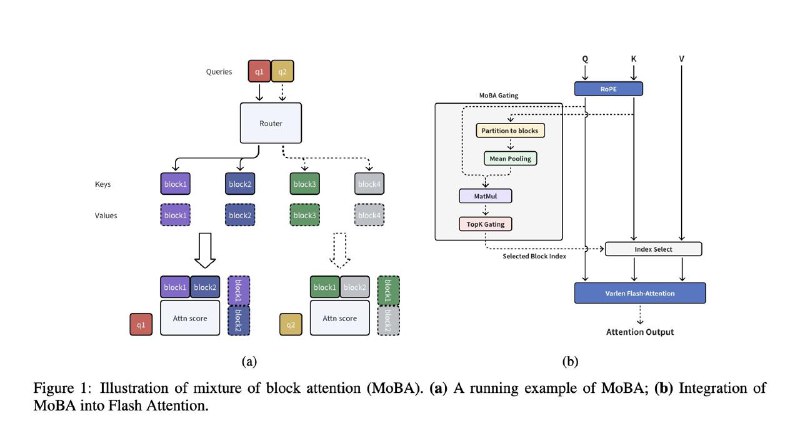
- Блочное разреженная внимание: Полный контекст делится на блоки, и каждый токен учится выбирать наиболее релевантные блоки, что позволяет эффективно обрабатывать длинные последовательности.
• Параметрически независимый механизм выбора: Внедрён механизм топ-k без дополнительных параметров, который автоматически переключается между полным и разреженным вниманием, что делает модель гибкой и адаптивной.
• Эффективность и масштабируемость:
MoBA обеспечивает значительное ускорение (например, 6.5x скорость при 1 млн входных токенов) без потери производительности, что особенно важно для задач с длинным контекстом.
• Практическое применение:
Модель уже доказала свою эффективность в продакшене и демонстрирует превосходное качество работы.
Проект MoBA будет полезен всем, работающим над масштабированием LLMs и задачами с длинным контекстом, предоставляя эффективный и гибкий механизм внимания, который можно легко интегрировать в существующие системы.
▪ Github
@machinelearning_interview
• Инновационная архитектура:
- Блочное разреженная внимание: Полный контекст делится на блоки, и каждый токен учится выбирать наиболее релевантные блоки, что позволяет эффективно обрабатывать длинные последовательности.
• Параметрически независимый механизм выбора: Внедрён механизм топ-k без дополнительных параметров, который автоматически переключается между полным и разреженным вниманием, что делает модель гибкой и адаптивной.
• Эффективность и масштабируемость:
MoBA обеспечивает значительное ускорение (например, 6.5x скорость при 1 млн входных токенов) без потери производительности, что особенно важно для задач с длинным контекстом.
• Практическое применение:
Модель уже доказала свою эффективность в продакшене и демонстрирует превосходное качество работы.
Проект MoBA будет полезен всем, работающим над масштабированием LLMs и задачами с длинным контекстом, предоставляя эффективный и гибкий механизм внимания, который можно легко интегрировать в существующие системы.
▪ Github
@machinelearning_interview
tg-me.com/machinelearning_interview/1567
Create:
Last Update:
Last Update:
✔ MoBA: Mixture of Block Attention for Long-Context LLMs представляет собой революционное решение для обработки длинных контекстов в языковых моделях. Вот что в нём интересно:
• Инновационная архитектура:
- Блочное разреженная внимание: Полный контекст делится на блоки, и каждый токен учится выбирать наиболее релевантные блоки, что позволяет эффективно обрабатывать длинные последовательности.
• Параметрически независимый механизм выбора: Внедрён механизм топ-k без дополнительных параметров, который автоматически переключается между полным и разреженным вниманием, что делает модель гибкой и адаптивной.
• Эффективность и масштабируемость:
MoBA обеспечивает значительное ускорение (например, 6.5x скорость при 1 млн входных токенов) без потери производительности, что особенно важно для задач с длинным контекстом.
• Практическое применение:
Модель уже доказала свою эффективность в продакшене и демонстрирует превосходное качество работы.
Проект MoBA будет полезен всем, работающим над масштабированием LLMs и задачами с длинным контекстом, предоставляя эффективный и гибкий механизм внимания, который можно легко интегрировать в существующие системы.
▪ Github
@machinelearning_interview
• Инновационная архитектура:
- Блочное разреженная внимание: Полный контекст делится на блоки, и каждый токен учится выбирать наиболее релевантные блоки, что позволяет эффективно обрабатывать длинные последовательности.
• Параметрически независимый механизм выбора: Внедрён механизм топ-k без дополнительных параметров, который автоматически переключается между полным и разреженным вниманием, что делает модель гибкой и адаптивной.
• Эффективность и масштабируемость:
MoBA обеспечивает значительное ускорение (например, 6.5x скорость при 1 млн входных токенов) без потери производительности, что особенно важно для задач с длинным контекстом.
• Практическое применение:
Модель уже доказала свою эффективность в продакшене и демонстрирует превосходное качество работы.
Проект MoBA будет полезен всем, работающим над масштабированием LLMs и задачами с длинным контекстом, предоставляя эффективный и гибкий механизм внимания, который можно легко интегрировать в существующие системы.
▪ Github
@machinelearning_interview
BY Machine learning Interview

Share with your friend now:
tg-me.com/machinelearning_interview/1567